Contents
In memory of J. Paul Morrison. May he rest in peace, and his work continue to live.
I started this article in 2018 as a collection of observations and ideas that I wanted to share with the Flow-based Programming community. It didn’t go beyond a quick draft that never got published. During the next 4 years I barely thought about Flow-based Programming. My focus was on figuring out how software is built in large companies. Interestingly, some of the observations I found in the enterprise software development overlapped with the use cases that I had drafted in this article. So I decided to give it another try and address it not only to the FBP enthusiasts but also to people who are not familiar with FBP yet and might benefit from it.
I kept postponing this work forever. Up until this Summer when I found out that J. Paul Morrison, the creator of Flow-based Programming, passed away this June at the age of 85. For me that’s a personal loss which shook me deeply. On one hand, because of the gratitude that I feel to Paul (aka JPM) for inventing this concept some 50 years ago and sharing it with the rest of the world. On the other hand, because I knew Paul personally, and I know how much effort he was putting recently into making FBP more attractive to the new generations of programmers. We even collaborated on a few projects to support FBP adoption, but sadly all that work was just a drop in the ocean.
What you’re going to find below is an introduction to the Flow-based Programming combined with deeper analysis of where and how it can be applied today or in the future.
Intro
Coding is about making software that works. Optimization is about making software work well. Design is about making software maintainable over time by teams of human beings.
A common learning path looks like this: first you learn to code, then you learn to write code that behaves well. Then you learn design patterns and start applying them reflexively. Then you learn to make reasonable design decisions. And then you don’t write code anymore, because you write documents and draw diagrams. Or because you have retired. Or you became a manager which is basically the same thing.
Jokes apart, design and coding usually come separately. So much separately that in a couple years of a project lifetime they have nothing in common. It’s a serious problem that many people ignore, and many others try to address. But nobody seems to have managed to keep the code and design diagrams 100% in sync all the time so far.
Then, what if I told you that somewhere in a parallel universe this problem doesn’t exist? In that universe they design the code and they code the design. If you don’t believe that universe exists, it reveals its main problem: it’s not so wide-spread and well adopted.
Let’s introduce that universe to more of our kind: Flow-based Programming.
What is Flow-based Programming?
Flow-based Programming (FBP) is a programming paradigm, which combines Dataflow programming with Component-based software engineering. In FBP, programs are networks of Components communicating via messages called Information Packets (IPs) sent through Connections.
Graphs and subgraphs
An FBP program is a graph. The nodes on the graph are called Processes and the edges are called Connections. The messages (IPs) flow through connections and processes use the data from these messages to do their work and send more messages. A typical graph can look somewhat like this:
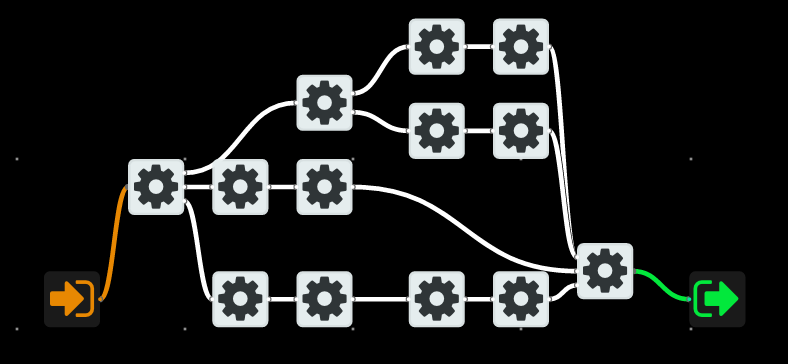
Processes run the code which is defined in Components. Think of Components as of Classes in OOP, and of Processes as of Objects being concrete instances of that Component. Similar to processes in your operating system, each Process in an FBP program is executed concurrently and independently of other Processes. Depending on a runtime, concurrency can be implemented with threads, system processes, coroutines, etc.
Data flows through connections from one process to the other. A connection may have a buffer and act as a queue, giving the receiver some time to consume all the messages. Or it can be a blocking connection, meaning that a sender has to wait for the receiver to consume the message. Some implementations (e.g. classical JavaFBP) use this sort of back pressure as a very important concept that allows for easier synchronization of and control of application’s throughput.
What are those boxes with orange and green arrows on the left and right of the graph? Those are its input and output ports. Because a graph is also a component and can be connected to the outer world by the means of its input and output ports. E.g. sending an initial config to the input port could be an entry point to your application.
There is also a textual Domain-specific language (DSL) for Flow-based Programming (FBP) which is actively used to save diagrams on disk or create diagrams when visual tools are not available or convenient. Below is an example of an .fbp diagram of an application that reads lines from a file, filters them by some criteria, and prints matching lines in console:
INPORT=ReadFile.NAME:IN # Input port
OUTPORT=DisplayLines.OUT:OUT # Output port
ReadFile(io/ReadLine) -> Filter(app/StartsWith) ACC -> DisplayLines(cli/Printer) # Main flow
Filter REJ -> IN Reject(Drop) # Using custom port names
Here are the main building blocks of an .fbp file:
INPORT=starts a declaration of an input port. It maps the portNAMEof theReadFileprocess to the portINof the graph itself.OUTPORT=is a declaration of an output port of the graph. In this case the portOUTof theDisplayLinesis mapped to theOUTof the graph.ReadFile(io/ReadLine)says that a processReadFileis an instance ofio/ReadLinecomponent. If you don’t see port names before or after the process default port names (INandOUT) are assumed.- Line #4 defines the entire main flow of the graph in one go. It instantiates the processes and connects them into a single pipeline using default port names.
ACCis one of the output ports ofFilterwhich means “accepted”. Filter REJuses a process that is already defined, no need to specify component in parenthesis.REJstands for output port namedREJ(“rejected”).- Line #5 defines the flow that drops rejected packets.
You can find a visual representation of this graph in the Strive for convenient IDE section.
Each node on the graph can actually be a graph itself, also known as a Subgraph. A subgraph looks just like any other graph, and there is no limit in how many levels deep your application can be. This nesting concept of Flow-based Programming is very powerful, because it helps keeping perceived complexity at a moderate level. Here is an example of how it could work for an application that receives data via some external interface, runs some business logic, and exposes the result via a message broker:
- Application.fbp would be your top level graph which contains a super high level outline of your application’s structure. At this level you see what the application does roughly and what subsystems it consists of, but all of them are subgraphs defined in their own diagrams.
- Api.fbp contains the input layer of the application that exposes an API, and translates data between external representation and internal messages
- Domain.fbp contains the business logic of the application. Each module there can be a separate graph
- Customers.fbp
- Orders.fbp
- etc.
- Messaging.fbp contains the output layer of the system, e.g. publishing data to a message broker
This is not necessarily the best and the most flow-based architecture ever, and you might prefer a different approach rather than this Input - Logic - Output slicing. For example, you could go with modules on a high level, and each module containing its own input and output components.
What is important here is that you actually see how your application is structured. You can zoom into a subgraph to see more details, and zoom out to see a more high level picture. And everything is connected, with connections pumping real data in your running application, not just a marker line on a whiteboard that is not relevant for good couple of years already.
Components
Visual languages are nice at high level and at describing structure, but when it comes to temporal dimension and describing behavior, traditional text languages are the king. In FBP, you can use them to write your Components. But first let’s look at what a Component looks like from the graph perspective (aka its interface):
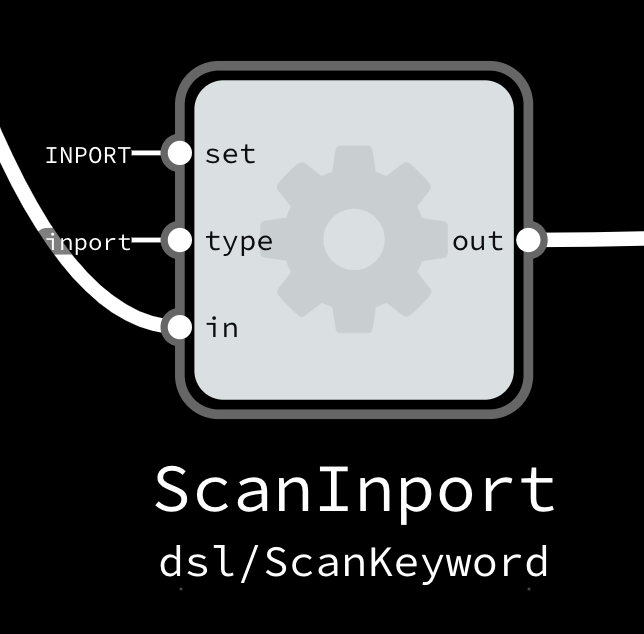
In this example, we have a process called ScanInport which is an instance of a component called ScanKeyword from the dsl package. It has 3 input ports and 1 output port:
setis a configuration input. For this component, it sets a keyword to scan fortypeis another configuration input, which assigns a specific type string with that keywordinis the main input which accepts a stream of incoming packets (messages)outis the main output port, which sends a stream of outgoing packets (messages)
As the interface suggests, this component is a keyword scanner for a domain-specific language tokenizer. It scans the incoming stream for the INPORT keyword and if it finds a match it sends the matched token to the output. The strings INPORT and inport that you see on the graph don’t have to come from any other processes. They are called Initial Information Packets (IIPs) and are sent once during program’s initialization.
What’s inside the component? Anything! The only constraint is that it has to read from its input ports and write to the output. Everything else is up to you: what to do with the data, whether to make it stateful or stateless, which libraries to use, persistence, UI, algorithms, you name it.
Still fancy some example code? Here is a snippet in Go that reads a stream of incoming files and passes the contents along:
// Reader reads a text files into packets.
type Reader struct {
Name <-chan string // input
File chan<- *File // main output
Err chan<- FileError // error output
}
// Process handles the input and transforms it to output.
func (c *Reader) Process() {
for name := range c.Name { // keep reading file names until the connection is closed
r, err := os.Open(filepath.Clean(name))
if err != nil {
c.Err <- FileError{
Name: name,
Err: fmt.Errorf("Reader failed to open the file: %w", err),
}
continue
}
data, err := ioutil.ReadAll(r)
if err != nil {
c.Err <- FileError{
Name: name,
Err: fmt.Errorf("Reader failed when reading the file: %w", err),
}
continue
}
c.File <- &File{
Name: name,
Data: data,
}
}
}
This component reads an incoming stream of file names. For each file it tries to open it and read all of its contents into a predefined message, and the sends it to the output and reads the next file. The code is a little bit verbose (hello, Go) with error handling. There are many ways to write a similar component, but you probably got an idea what you can do inside of components.
Comparison with other approaches
This table may help you understand how Flow-based Programming is similar or different from other approaches:
| Criteria | Flow-based programming | Dataflow programming | Imperative programming |
|---|---|---|---|
| Mindset | Data flows through the program and operations transform the data | Data flows through the program and operations transform the data | Operations are executed on data in certain order under certain conditions |
| Program model | A program is a graph of connected components | A program is a graph of connected components | A program is a sequence of instructions |
| Model visualization | Data flow graph | Data flow graph | Control flow chart |
| Representation | Visual (graphs) + Text (components) | Visual (typically), Text (sometimes) | Text |
| Parallelism | Implicit: all operations are parallel by default | Implicit or explicit, depends on framework | Explicit: parallelism needs to be programed |
| Control model | Active: components control their lifecycle | Reactive: components are activated by external events | Active: components control their lifecycle |
What makes Flow-based Programming special among other dataflow programming tools is:
- 2 engineering perspectives: Graph (visual) and Component (textual). Components describe the behavior of data transformations. They are typically pieces of conventional code written as text files. Graphs define how data travels between Components. Graphs are typically visual or at least written in a declarative language.
- Any Graph is a Component itself and may include other Graphs. Nesting allows for decomposing the program into comprehensive parts. Think of being able to zoom into each component to see what’s inside.
- Component interface consists of input and output Ports. At the same time, Ports are the primary means of interacting with the outside world from inside the Component. Each component can have multiple input and output ports (compared to single-port components in many dataflow systems)
- Components actively read the incoming data and decide how to react to it. This is different from reactive programming, where reaction functions are automatically fired on events by the runtime.
- Components run concurrently and share no state. But inside each component can be either stateful or stateless.
- The messages (IPs) are typically self-contained objects rather than just primitive values, which makes communication and synchronization more effective. Think of them as Data Transfer Objects rather than just scalar values.
- Flow-based systems perform parallel computations by default. All components in the graph are independent and run in parallel.
If you are into studying FBP, I recommend you to start with the Flowbased wiki.
Where is it applicable?
Flow-based programming applies most naturally to domains which already have the notion of components, black boxes, processes, pipelines, etc. In particular, FBP is very attractive in:
- Bioinformatics
- Data engineering, e.g. ETL
- DevOps
- IoT
- Low-code systems
- Machine Learning
Is this just guesswork or based on real data? Sources of these conclusions are:
- a questionnaire sent on Flow-based programming mailing list a few years ago
- a questionnaire I posted in GoFlow repository on GitHub
- my observations around the FBP community on the mailing list and Twitter during the last 10+ years
Originally introduced as a general-purpose programming paradigm, Flow-based programming has also been applied successfully to other domains such as:
- Business applications
- Web services
- UI applications
Despite the fact that originally FBP was applied to transactional Banking software where it was used rather successfully for a good sequence of years, in the present days it is probably not the best tool for these use cases. For example, building a massive web service for your business is probably done faster and easier with a conventional framework like Spring than with FBP.
Problems it solves
IMO Warning. Everything that you are going to read below is my personal opinion. I’ve been participating in the Flow-based Programming community for 10 years, built an academic framework, and a few commercial Flow-based systems that worked in production. All the statements in this and the following sections are based on my own ideas, observations, and fallacies. Trust it at your own risk.
When I started to learn Flow-based programming in 2010, it had a massive wow-effect on me and seemed like the ultimate paradigm I want to be using from then till the point when AI replaces programmers at work. That was naive, in multiple ways.
A decade later, I still think Flow-based Programming has several important advantages that the mainstream software industry is missing. However, these advantages are not the same ones which I anticipated in the beginning. In this section I will share the modern Software Engineering problems (not Programming problems!) that Flow-based Programming successfully solves.
Comprehensibility of Software systems
Humans absorb new information much quicker when it’s supported by visuals. When looking at a software system for the first time, we understand a diagram much quicker than a few hundreds lines of code that it describes.
Most software projects start on a piece of paper or on a whiteboard because that’s just easier to start reasoning about things.
With FBP, they continue living on a board. At any point of time you can see on a diagram how an application is structured and how it behaves.
Evolution of Architecture vs. Code
In conventional software development cycle, diagrams get abandoned soon after the implementation starts. It’s very hard to keep both diagrams and code up to date, especially over a long period of time. Even if the original team was pedantically updating the diagrams every time they made changes to the code, the next maintainers may not be so consistent with it.
There is an opposite approach when the diagrams are generated from code. With that approach you can get relevant diagrams at any time, but the resulting diagrams are complicated, because they are a byproduct of the implementation process, rather than a design guidance. E.g. an autogenerated Class diagram is very useful when studying the structure of the codebase. But when you need to drive high level architectural changes, you cannot just start with diagrams as they are autogenerated and you have to update the code first.
In FBP, diagrams are code. Problem solved.
The C4 model
The C4 model is another way of visualizing software architecture that started gaining a lot of momentum recently, especially in the Enterprise. The “C4” stands for 4 levels or views on the architecture of the software systems:
- Context - high level overview and usage of the system in a broader context
- Containers - deployment units
- Components - building blocks
- Code - classes and low-level implementation
An example Components diagram is given below:
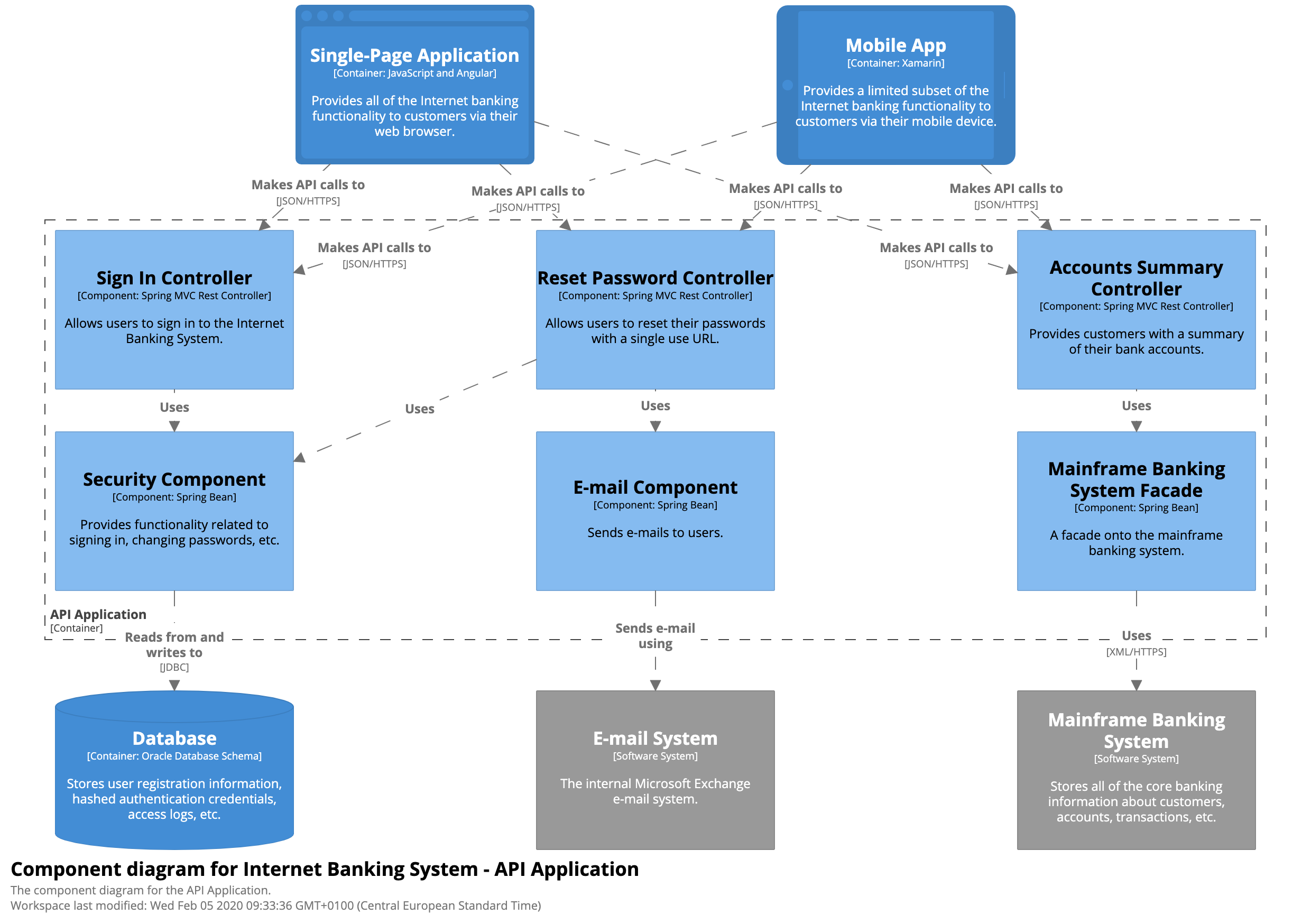
C4 is a very powerful and expressive model. No wonder it is gaining popularity and is featured on the ThoughtWorks TechRadar as a headliner of “Diagrams as code” approach. It is supported by many tools and comes with some useful extensions.
With C4 extension for PlantUML you can use PlantUML as a free diagramming tool, and save the diagrams in a human readable text format, that is easy to store in version control systems. With PlantUML, you can put your diagrams next to your code on Github, and track changes to those in diffs and pull requests.
Structurizr, a proprietary product from the creators of the C4 model, has gone even further. It proposes its own Domain Specific Language (DSL) which is optimized for describing software architecture. There were plans to create a code generator, that would generate boilerplate code from the C4 diagrams. I couldn’t find any implementations of such a generator so far though.
Autogenerating code from diagrams or autogenerating diagrams from code is convenient. Storing diagrams as a compact and human-readable DSL next to the code is definitely a huge step forward from the traditional diagraming tools which produce raster images.
However, just the fact that the diagrams are stored next to the code does not guarantee that they actually reflect what is in the code, and vice versa.
It is still a matter of building an organizational routine to make sure that diagrams and code are up to date. For many programmers, it means just extra steps and duplicate work.
This is where Flow-based Programming shines: in FBP, diagrams are part of the code that runs the system. Diagrams glue system’s components together and you need to update the diagrams in order to update the application.
Having worked with C4 in a large organization and on large systems, I can share that C4 diagrams can get messy. If the system gets large and complex enough, its components (or even containers) diagram can hardly fit on any screen or in anyone’s head. This makes me miss the concept of subgraphs from FBP so much. I would rather split a large diagram into multiple cohesive sub-diagrams, and work with them on individual layers, rather than trying to understand or modify everything at once.
Granularity of Dataflow systems
The main issue with dataflow approach is that it often gets too granular and low level. It is not uncommon in dataflow systems to have diagrams the size of a tennis-court with hundreds and hundreds of components on them. There are too many details on such diagrams.
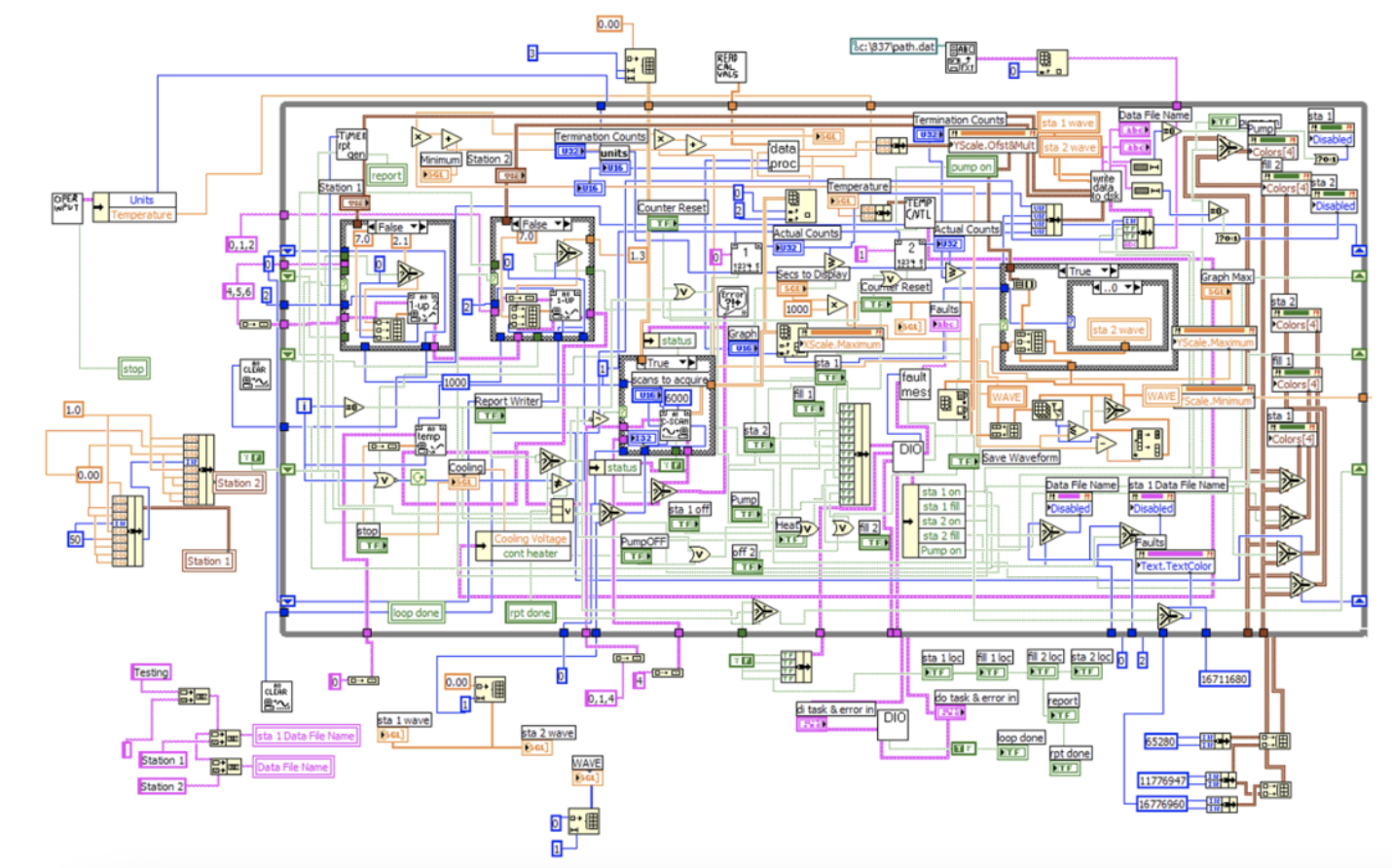
With FPB, you write low level components in conventional textual programming languages. Those languages were created to describe behavior, so let the tool do its best job. And then encapsulate implementation details behind the component interface.
You can choose any level of granularity: from atomic operations to large subsystems represented as Components.
The optimal choice usually sits somewhere in the middle. A good FBP component is like a good class in OOP: it does more useful work than just a single-liner, but it doesn’t do too many things so that it’s easy to reuse and maintain.
“Vendor lock” to a specific language
Some dataflow languages force you to implement everything either with the visual language itself, or with a low-level language that it is implemented in (e.g. C).
With FBP you don’t need to reinvent all the wheels, you just use existing libraries and your favorite language inside the components. Cross-language and remote communication is encouraged by use of FBP Protocol, meaning that your application can as well be written in different languages or distributed across different machines.
Problems it does not solve
Just like any other thing, Flow-based programming is not a silver bullet. There are some problems people believe it to solve but in fact it doesn’t or it does only partially.
Designing clean software without effort
Clean design of software systems doesn’t come for granted. Flow-based Programming is no exception. Best described with a quote from Henri Bergius:
In FBP, your spaghetti code actually looks like spaghetti.
You still have to work hard and apply your best knowledge to design clean software with FBP.
The bad news is that many existing software patterns simply don’t work when you change perspective from control flow to data flow. For example, if you try to implement MVC with complex Data Abstraction Layer glued by Dependency Injection, it is going to end up in a huge mess you stop understanding just 5 minutes after you create it. It is better to implement such things on top of the conventional frameworks.
There are a few patterns which work effectively (e.g. Assembly line), and there are more to be discovered by trial and error.
The good news is that it’s way easier to spot when something is wrong with the architecture of a Flow-based system, because you can actually see it.
Building software faster
Programmers often seek a new paradigm because they believe it will make their life easier. Many FBP enthusiasts believed that FBP will make them more productive.
When somebody enters the world of Flow-based (or Dataflow) Programming, they typically expect some or all of the following to be true:
- Components are largely reusable (see “Having no code to write” below)
- Component code is less error prone (which is arguable) or at least easier to test (which is often true)
- Seeing the data flow in the visual debugger being easier than using a traditional debugger
- Editing visual diagrams being much faster than typing text
The expectation is that these 4 statements are true and that it automatically translates in a significant speed up of the development process. In reality the speed of building software depends on the following basic factors:
- How well you know the tool
- How many building blocks already exist
- How much essential complexity is contained in the problem you solve
There is also the component of accidental complexity, but I would really like to emphasize the essential complexity part. If that sounds too “control flow”, entropy of the system is a similar metric. The law of information science says: your program cannot be more simple than the problem it solves. A.k.a. No Silver Bullet.
Having no code to write
Another delusive expectation from FBP is that the community can write such a library of reusable components, that later on there is very little code to be written. You’d drop the existing components into your graphs and that’s it.
This assumption made people concentrate on writing components which are either too small or too generic. Which made neither of them easy to use. With very fine-grained components your graphs get too big and too convoluted. With very generic components you end up writing a lot of adapters and workarounds. So, when it comes to component scale, the golden mean works the best.
If your application is not just an example of a library usage, and rather solves some business or user problem, it means that you have to write a lot of components specifically for your application.
FBP can be used to build a Low-code or a No-code development platform. One of the early attempts was e.g. Flowhub. However, FBP is not alone in that niche today.
Issues of parallel and distributed systems
Originally it was thought that as all Processes run in parallel, and there is single ownership rule (each Information Packet is only owned by one Process), all concurrency issues are solved inherently.
Some of them are: in FBP you design your program as a concurrent system from the very beginning, so you have to think how the data flows between parallel branches in the graph from day one.
But the coin has the other side: as all Processes may run in parallel, you need a lot of synchronization. Especially in long-running applications processing concurrent requests.
And there goes the the problem of distributed transactions. FBP hasn’t escaped it automagically.
In other words, FBP makes parallel programming more visual, but all of its issues still have to be solved by a person who designs an FBP program.
Can I use FBP today?
Yes, e.g. with:
- Elixir: ALF, ElixirFBP
- Go: GoFlow, Flowbase, Cascades
- Haxe: ZenFlo
- Java: JavaFBP + DrawFBP
- JavaScript: NoFlo + Flowhub
- PHP: Railway-FBP
- Python: multiple packages
- Rust: Fractalide
- probably with your other favorite language, Google knows how many Flow-based Programming runtimes are around.
Will it be easy? Maybe yes, but most probably not. Unfortunately we are not in a state when we can just throw all the UML and piles of classes away and switch to Graphs and Components all of a sudden. There are some important problems to be solved first. In particular, the learning curve may be steep both because of the paradigm shift and because of maturity of existing tools.
Challenges of Flow-based Programming adoption
This section covers the problems faced by people who want to get started with Flow-based programming, as well as other factors that explain why FBP is not so popular yet. To be more constructive, I suggest some steps to overcome those issues.
The barrier of entry
Getting started with Flow-based programming is not easy. From day one a new joiner has to overcome the following obstacles:
- Shifting a mental paradigm from classes, methods, loops and ifs to components and data streams
- Lack of documentation and examples of solving real world problems
- Complicated integration with existing software
- Lack of tooling, including a modern and convenient IDE
More on these problems and potential solutions below.
The strive for a convenient IDE
Presently there are two big players in this market: DrawFBP and Flowhub. And they are the very opposites of each other.
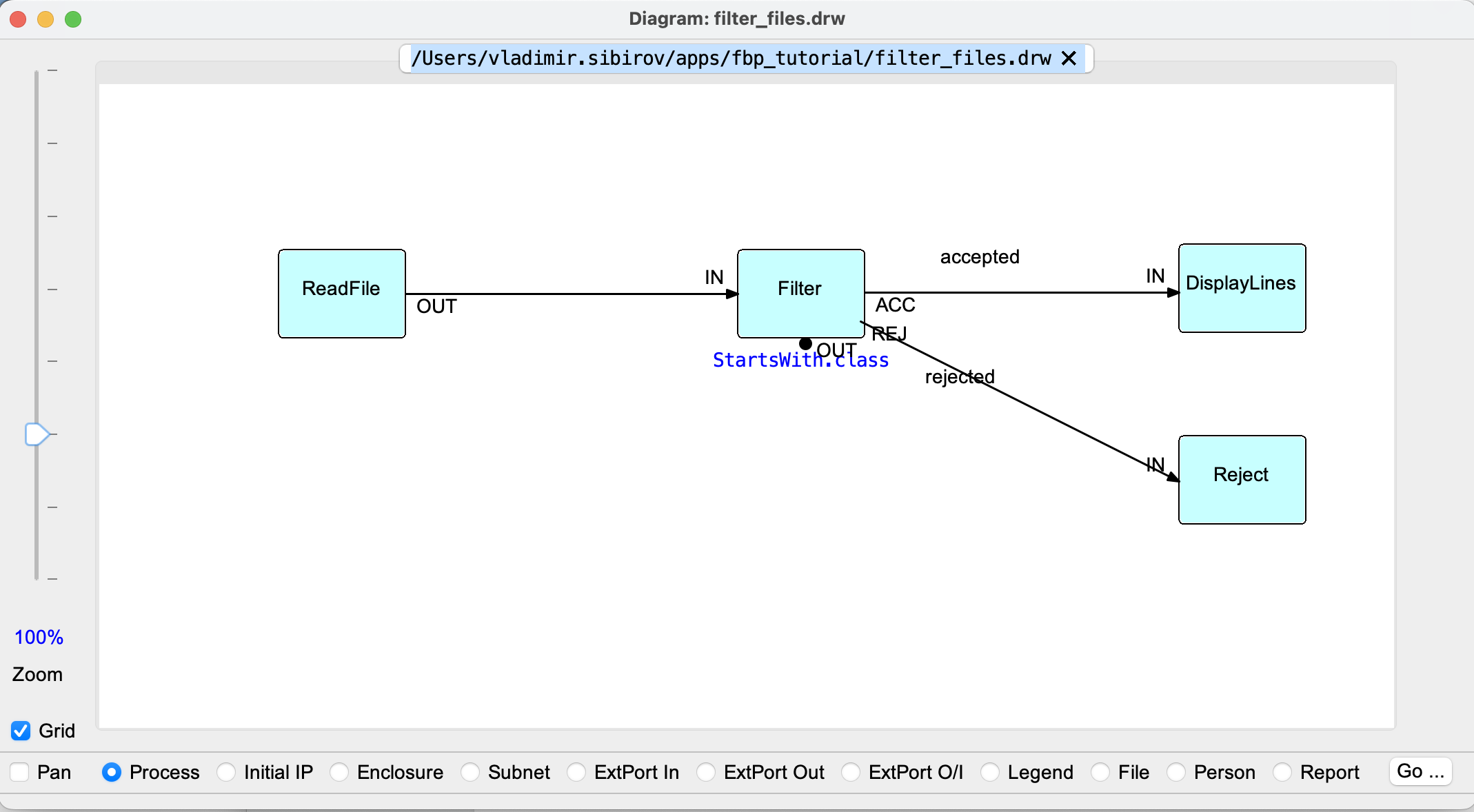
DrawFBP is a Java app that was started long ago and its interface isn’t very appealing to programmers of the modern days. It uses very own UI flows to create FBP diagrams. It also comes with a code generator feature which works best for the classic JavaFBP. But it doesn’t support universal .fbp or .json graph notations and isn’t very useful for anything than just sketching (hello, UML) if you use a runtime that is not explicitly supported by this tool.
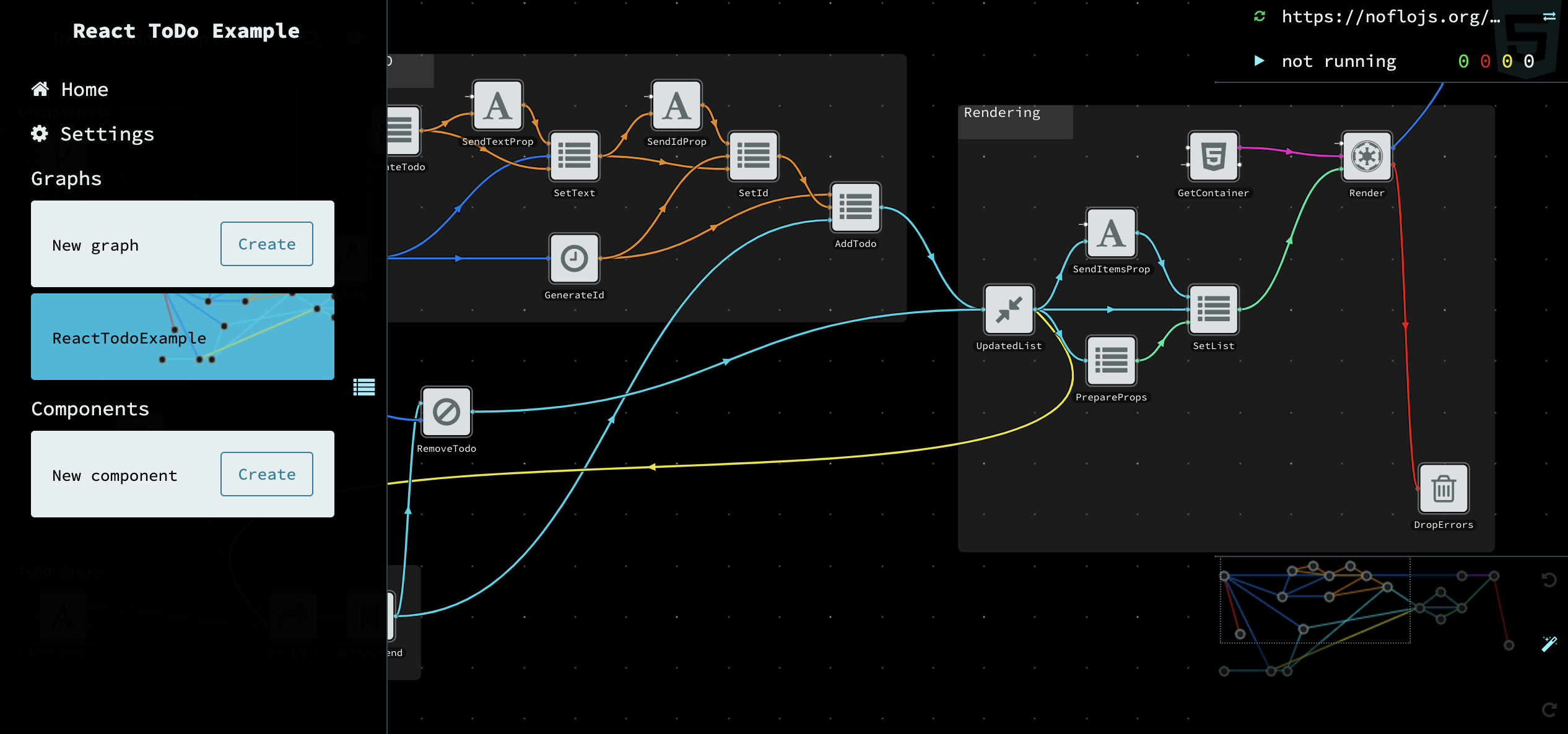
Flowhub (and its open source sister Noflo-UI) is an app that runs right in your browser, and it’s an IDE which does everything: edits graphs and components, saves projects on GitHub, runs tests, talks to the runtime, introspects the running application. And it does so by making use of universal protocol and file formats. Flowhub had a lot of amazing features in the peak of its popularity around 2015, but it didn’t really dominate the market of Software Development Tools. IMO, for the following reasons:
- The hosted version is not a full package: the IDE is in the cloud, but you need to set up and host the runtime part of your application manually
- If you run the NoFlo-UI yourself, it becomes too many parts that you need to manage, which slows down the development process
- The IDE is very smart, but when you need to do something out of ordinary, that is very likely unsupported and you have to hack it around
- Local debugging is complicated
I can see two directions that FBP IDEs can follow. And those are quite opposite.
A simple and convenient Graph Editor
Many of us FBP hackers are control freaks and fans of simple and tangible tools. We don’t like heavyweight IDEs, especially if they are hosted and controlled by some 3rd party company renting as a subscription.
What we need is neither Blender nor Eclipse. What we need is more like Visual Studio Code these days. We want something that can edit .fbp and .json files in a visually appealing and intuitive way. And that’s it for now. The rest can be done by firing up a command in CLI. We want to try things fast locally and see how they work/break. So if we had something that looks like Flowhub but edits local graph files, it would be just enough. If it would be just a plugin for VSCode, that’s even better!
A cloud IDE
Some of the new comers, especially people attracted by Low-code and No-code concepts, prefer the IDE to do most of the work for them.
They need something like Flowhub but better: automatically hosting the application runtime somewhere in AWS, GCP, Azure, etc. Some people around Dataflow and Flow-based programming communities are actually working on such IDEs. But having experienced the development of Flowhub first hand, I can tell that it’s a very complex and expensive journey.
Integration with existing software
FBP runtimes/libraries/frameworks should be easy to embed in existing projects. NoFlo’s asCallback is a good example of such embedding feature.
Clean API, documentation, and examples are of undoubted importance. But programmers want to be able to start with what they already know and have.
When looking at business customers rather than individual hackers, integration into existing systems is even more important. Greenfield projects are much more uncommon rather than a bunch of existing services or a good old monolith. When bringing a new tool to the table, such as FBP, the expectation of a business is that it should add value rather than sacrifice what’s already there.
Discovering best design practices
There is a big mindset shift when switching from control flow thinking to data flow thinking. Difficulties don’t end there though. Building something larger than a quick example application typically raises a lot of questions:
- How to split layers? Should I go for Model-View-Controller, or Data-Application-Presentation?
- Should there be layers at all?
- Package components by graphs or package components by function?
- Multiple inputs vs. single input
- Bulky everything-and-a-kitchen-sink messages vs. small objects
- How to pass state?
- Representing and controlling transactions
- How to reuse logic between components?
And many more. Trying to find an answer in a book on Object Oriented Design Patterns typically doesn’t help, because most of those patterns and best practices were created with control flow in mind. Switching a paradigm brings a challenge of collecting best practices from scratch, piece by piece.
You can use SOLID principles to design components though. Well, perhaps except for the Dependency Inversion Principle, because abstractions are not so easy in FBP. Liskov Substitute Principle also would require extra effort compared to OOP. But Single Responsibility, Open-Closed, and Interface Segregation are certainly helpful.
Not invented here
One pattern that clearly exists in the Flow-based Programming community is called “Not invented here”. Many enthusiasts who get excited and inspired by FBP set on a journey of creating their own FBP framework, IDE, or entire paradigm. There can be multiple reasons for that, e.g.:
-
Exploring the concept and playing with code to understand it better
-
Building something very niche to what the person is working on
-
Having a strong personal vision of how to “get it right”
-
Believing in the uniqueness of their solution instead of power of collective effort
No matter what the reasons are, the fact is: very little collaboration happens in the community. Which is very unfortunate, because it takes a lot of effort and typically a lot of collective effort to get a technology to a state where it can grow its popularity organically.
Frankly speaking, if you ask me “why hasn’t Flow-based Programming become popular in the last 20 years?” my answer will be: because everybody was too busy building their own versions of it. Changing this attitude is a must for FBP to grow from striving to thriving.
Beyond Flow-based Programming
In this section I try to go beyond just writing code and think out loud about the areas where Flow-based Programming may find powerful synergies in the next few years.
Microservice orchestration
No, this is not Kubernetes again. I mean service orchestration not container cluster orchestration. One of the interesting use cases that FBP may have is providing a higher level view on systems of microservices. Microservices can be small enough to be considered as Components, and message bus can be used as a transport layer for Connections. Value that FBP adds on top of what is already there is:
- Visualizing system architecture at higher level, with the picture being always up to date. Think of something like Netflix Vizceral, but more declarative rather than descriptive
- Standardizing the interface and communication between services via a messaging system. REST and gRPC are popular when talking over a synchronous HTTP layer, with messaging systems it’s more wild. Exposing an interface of a microservice as a set of ports receiving/publishing messages of a certain type could be an interesting approach
- Providing real-time introspection of cross-service communication (if implemented)
This is the direction where e.g. Cascades FBP was going. It wouldn’t be very surprising if something similar exists outside of the FBP world, especially in the Enterprise sector.
Stream processing
Many large organizations nowadays embrace the use of stream processing frameworks, such as Kafka Streams, Apache Flink, and others. Most of them are used for data processing, but some frameworks are generic enough to be used to create business applications end-to-end. Most of these solutions are based on Apache Kafka underneath.
OK, let me put it differently: Kafka is eating the world. And after being eaten by it, engineers at companies start thinking: if in data analytics everything is a stream, isn’t everything everywhere a stream? Panta rhei? Let’s figure it out!
As a more general purpose framework rather than a data analysis tool, Kafka Streams is far ahead of everyone, it doesn’t really have competitors. So much so, projects like Goka inspired by Kafka Streams start to emerge.
In a way, this brand new world of distributed stream processing looks very similar to FBP systems from 30 years ago. The major difference is: FBP missed the distributed component, and stream processing frameworks completely miss the visual part. Kafka Streams even has a topology DSL that reminds of FBP graphs, e.g.:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000 (topics: [conversation-meta])
--> KSTREAM-TRANSFORM-0000000001
Processor: KSTREAM-TRANSFORM-0000000001 (stores: [conversation-meta-state])
--> KSTREAM-KEY-SELECT-0000000002
<-- KSTREAM-SOURCE-0000000000
Processor: KSTREAM-KEY-SELECT-0000000002 (stores: [])
--> KSTREAM-FILTER-0000000005
<-- KSTREAM-TRANSFORM-0000000001
Processor: KSTREAM-FILTER-0000000005 (stores: [])
--> KSTREAM-SINK-0000000004
<-- KSTREAM-KEY-SELECT-0000000002
Sink: KSTREAM-SINK-0000000004 (topic: count-resolved-repartition)
<-- KSTREAM-FILTER-0000000005
This DSL is neither easy to read, nor to write. And it needs a translator to visualize.
Big companies don’t see it as a problem. They can hire a bunch of specifically trained Kafka Streams engineers or spend a few quarters educating them. For smaller players comprehensiveness of these stream processing systems can be a deal breaker.
Flow-based Programming has some nice things to offer here:
- A visual paradigm. And a more human-friendly text DSL if needed
- Subgraphs. No more “whole enterprise in one 1000 component diagram” mess
- Port declarations as data for schema registry
- Visual introspection and troubleshooting
A combination of Kafka Steams’ resilience and high throughput with Flow-based Programming’s comprehensiveness and developer orientation could step up the game in the world of stream processing.
Low-code and AI assistants
As I showcased above, previous attempts to use Flow-based Programming as a foundation for no-code or low-code frameworks failed. Neither was there enough hype around no-code, nor were these systems that effortless.
In 2022 and beyond this situation can finallys change. Not only because of the hype, but also because of the general availability of AI code assistants.
One of the FBP issues I mentioned above is that you actually have to write a lot of components, both common and custom. Using assistants like Github Copilot or Kite can be a game changer there. Components are typically just functions. A function signature and a thorough description is enough for Copilot to suggest an implementation. It’s not going to code the whole library for you, but with it you can do it much faster.
Closing words
Thank you for getting through this wall of text, abstract ideas, and concrete rants. I hope that you found some of it useful, and some of these thoughts resonated with you.
I’m pretty sure I didn’t cover everything around different FBP frameworks and tools that exist today, that wasn’t my intention for this article. If I missed some important bits, feel free to reach out to me. Maybe I come up with such an overview at some point in future.
If you want to start a conversation about this article or any topic related to FBP, you can join the FBP community on Discord.